Go - EXIF Scanner and Extractor
Using Go to extract EXIF data from Image files
Extracting EXIF from a single file is easy but suppose you have a huge folder tree with hundreds or thousands of images, what then? Then suppose you have a publishing deadline for a book. What you need is a super fast, efficient language to do the job for you. Golang is what you need!
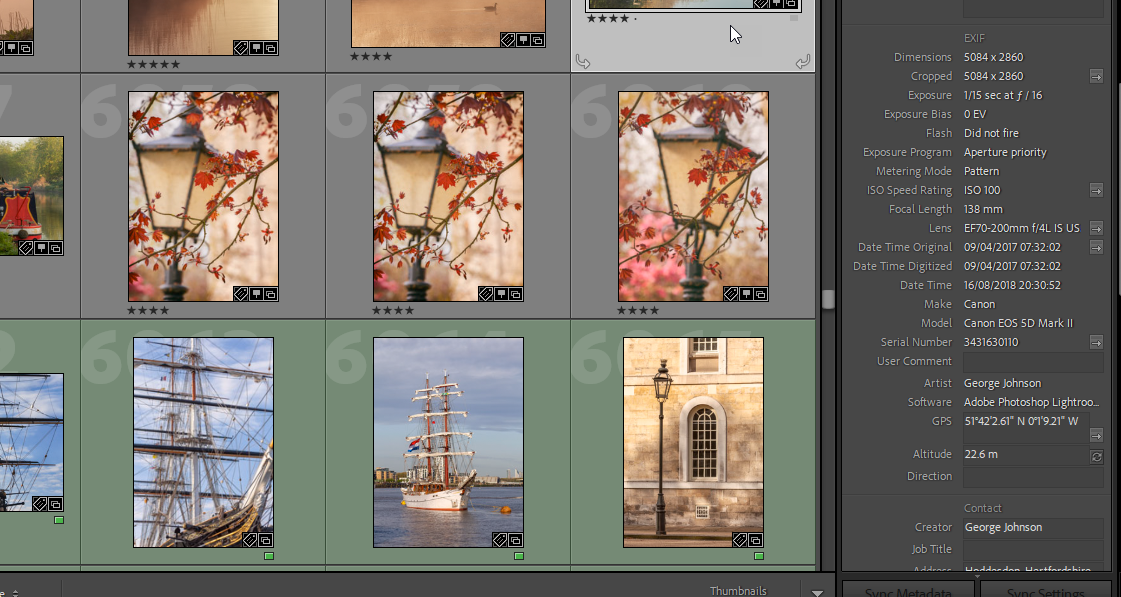
Have you ever wondered how when you take photos using your mobilephone and then upload them to your favourite website, how does it know so much about the phote image file? The secret is the EXIF data stored within the JPG images you capture and then upload. The EXIF data contains the most critical info needed about an image, the camera, the lens, the focal length, aperture size, time and date of the shot and even the GPS info. This is the most basic info, on top of that there are extensions for the IPTC info which has tons more info like keyword trees, descriptions, copyright, all valuable stuff you store and maintain using software like Adobe Lightroom.
When I worked on my first photo book for FotoVue I'd shot and edited around 3,000 images files, from those we selected around 1,000 images to go into the book. The books FotoVue produce are for photographers and that means you need to have the key informaiton like location, camera, lens, focal length, aperture, ISO, all that good stuff and one place that's stored is in the EXIF of every image. When you edit all the info is kept and stored so it can be used to correctly catalogue your images.
Getting the EXIF from a single image is dead easy, right-click on it select Propeties ( Windows ) or "Get Info" ( Mac ), there it is. How the heck do you do that for 1,000+ images that are scattered through sub-folders? The London book I worked on had 12 chapters with 14 locations per chapter, that's around 200+ sub-folders. We needed the key critical EXIF data into something we could pass to the page designers, so we needed the filename plus the EXIF data, they would then copy and paste it into the 1,000 images in the book's layout.
We thought Lightroom could be used to get the info but despite it begin one of the best photo image organisers available it's useless at allowing you access to it's internal database, it demands you jump through some severley archais hoops using LUA, I've no wish to learn a dead language from scratch just to get a CSV.
Enter the Gopher!

Luckily Go is a best damned language on the planet and I needed a simple Go project to get me started as I was learning Go.
Go-Exif Libary
We need a library that can extract EXIF data from any JPG file and hand it over in a simple text based format.
The examples supplied with the library are superb and ready to be built, so I stripped out the requied code and then built myself a file-folder scanner using the filewalk function from the standard library. From that I was able to put together a suitable struct, read the info from file in a tree and dump the whole damned thing back out to a CSV file that could be loaded into any suitable spreadsheet app.
You can find the code for my EXIF scanner extractor here: GOExifExtractor on Github
The GOExifExtractor Utility
The reason for choosing Go was that I use Windows and Linux but others may use Mac, most togs will use Macs to manage photos and while it's a command line only util I needed a way to use it on any of the major platforms, Go can cross compile, so that's sorted.
The utility allows you to choose the fields you like to extract or simply all of them, filling in blanks where it can. The most common EXIF fields are shown below:
1constEXIFFields = []string{
2 "ImageDescription",
3 "Make",
4 "Model",
5 "Software",
6 "DateTime",
7 "Artist",
8 "Copyright",
9 "ExposureTime",
10 "FNumber",
11 "ISOSpeedRatings",
12 "DateTimeOriginal",
13 "DateTimeDigitized",
14 "FocalLength",
15 "CameraOwnerName",
16 "BodySerialNumber",
17 "LensModel",
18 "GPSLatitudeRef",
19 "GPSLatitude",
20 "GPSLongitudeRef",
21 "GPSLongitude",
22 }
The folder scanned it really simple, nothing more than a simple JPG scanner. ( yeah hardcoded JPG only, it was my first Go project! )
1err := filepath.Walk(filepathArg, func(path string, info os.FileInfo, err error) error {
2 if filepath.Ext(path) == ".jpg" || filepath.Ext(path) == ".JPG" {
3 files = append(files, path)
4 }
5 return nil
6 })
One thing that I did have problems with was how the raw EXIF data is stored from some attributes, the two problematic ones were Exposuretime and Aperture setting sometimes called the F-number, often expressed as f/16 for example.
Exposure
Exposure is stored in EXIF as an expression of a fraction of a second. Sub-second that is something like 1/128, which is 1/128th of a second. That's easy enough. However anything longer than a second, long exposure images can be minutes, is stored as fraction 60/1, which is obviously 60 seconds. So that needed to be split and converted to decimal then have "sec" appended. Simple enough with a couple of floats.
Aperature
Aperature is expressed as a ratio of the the focal length and width of the aperture, so f/8 or f/16. There is no actual value on a lens of f/8 or f/16, they are simply ratios of the relationship between the settings of where the lens has been set and the aperture. Once again, we take the value from the EXIF and convert it from fractional to decimal then append "f/" to the result so that it makes sense when shown in the CSV.
Go-Exif Library
The core function of the Go-Exif library is to be presented with an image file, it then extracts all the EXIF data a JSON based struct. We then cycle the info brought back from the image file in the struct and pull the EXIF field we actually asked for, converting those mentioned where required for the CSV output. The real magic is that the Go-Exif library is able to extract the data into a really easy to use data format where the fields are just sets of tagged data.
Is it Worth The Effort?
All I can say is that when FotoVue books are put together gathering the EXIF data and extracting it can take one person around a week to get all the info if they spend every day copy and pasting the info from Lightroom into Excel! That's a week of click and image, copy 8-10 pieces of text per image from Lightroom into row in Excel, then repeat around 1,000 times!! No fecking way! I didn't spend 30 years of my life in IT for nothing!
I use Lightroom along with Jeffrey Friedl's superb "Collection Publisher" plugin for Lightroom to extract and dump all the images in the correct folder structure on disk to match the collections from within Lightroom. Then I run my scanner over it and I can have a 1,000 JPG file's worth of data into a CSV in less than 2 mins! 2 mins versus 60 hours of manual copy'n'paste, f**k yeah it's worth it!
If the EXIF data is wrong or not quite right, then I don't have to spend hours and hours fixing a spreadsheet, I simply fix the odd entries, re-dump the images I need and then re-run the util, all of which can be done in a few minutes. This means the data can be off to the book editor and layout artists same day, it's easier to fix if there's problems so the turnaround is infinitely faster and it means me, the editor and layout artist have much more time to do the creative stuff we enjoy. All thanks to Go and a will to automate.
Links: